深入分片
4.1 使文本可以被搜索
倒排索引存储了比包含了一个特定term的文档列表多地多的信息。它可能存储包含每个term的文档数量,一个term出现在指定文档中的频次,每个文档中term的顺序,每个文档的长度,所有文档的平均长度,等等。这些统计信息让Elasticsearch知道哪些term更重要,哪些文档更重要,也就是相关性。
需要意识到,为了实现倒排索引预期的功能,它必须要知道集合中所有的文档。
在全文检索的早些时候,会为整个文档集合建立一个大索引,并且写入磁盘。只有新的索引准备好了,它就会替代旧的索引,最近的修改才可以被检索。
写入磁盘的倒排索引是不可变的,它有如下好处:
- 不需要锁。如果从来不需要更新一个索引,就不必担心多个程序同时尝试修改。
- 一旦索引被读入文件系统的缓存(译者:在内存),它就一直在那儿,因为不会改变。只要文件系统缓存有足够的空间,大部分的读会直接访问内存而不是磁盘。这有助于性能提升。
- 在索引的声明周期内,所有的其他缓存都可用。它们不需要在每次数据变化了都重建,因为数据不会变。
- 写入单个大的倒排索引,可以压缩数据,较少磁盘IO和需要缓存索引的内存大小。
4.2 动态索引
下一个需要解决的问题是如何在保持不可变好处的同时更新倒排索引。答案是,使用多个索引。 不是重写整个倒排索引,而是增加额外的索引反映最近的变化。每个倒排索引都可以按顺序查询,从最老的开始,最后把结果聚合。
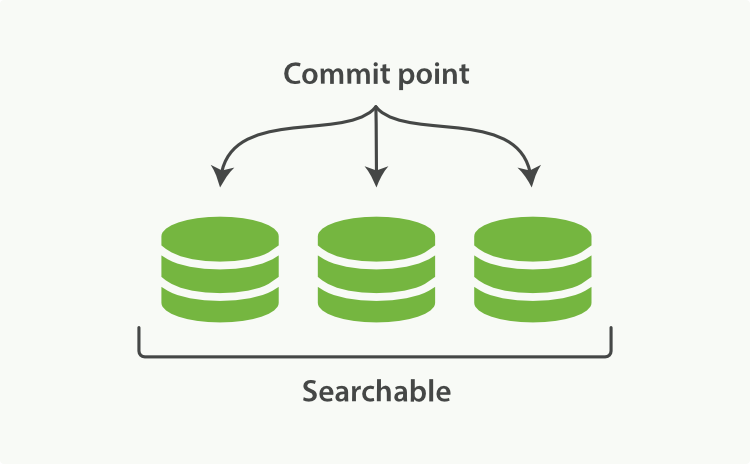
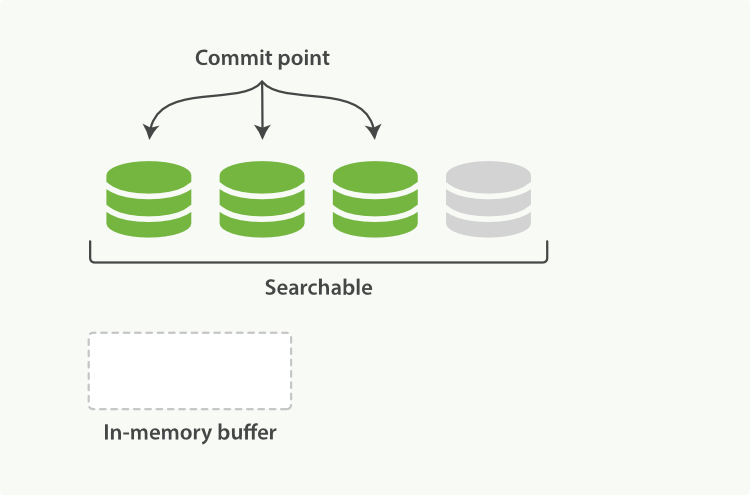
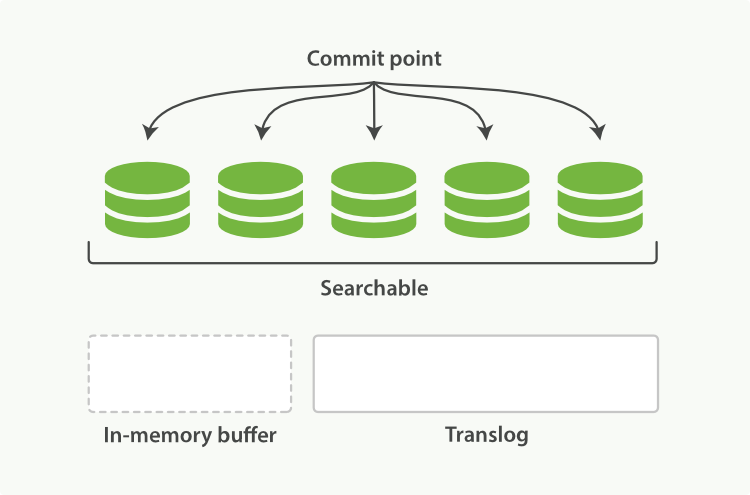
Elasticsearch底层依赖的Lucene,引入了per-segment search的概念。一个段(segment)是有完整功能的倒排索引,但是现在Lucene中的索引指的是段的集合,再加上提交点(commit point,包括所有段的文件),如图1所示。新的文档,在被写入磁盘的段之前,首先写入内存区的索引缓存,如图2、图3所示。
图1:一个提交点和三个索引的Lucene
一个per-segment search如下工作:
- 1.新的文档首先写入内存区的索引缓存。
- 2.不时,这些buffer被提交:
- 一个新的段——额外的倒排索引——写入磁盘。
- 新的提交点写入磁盘,包括新段的名称。
- 磁盘是fsync’ed(文件同步)——所有写操作等待文件系统缓存同步到磁盘,确保它们可以被物理写入。
- 3.新段被打开,它包含的文档可以被检索
- 4.内存的缓存被清除,等待接受新的文档。
图2:内存缓存区有即将提交文档的Lucene索引
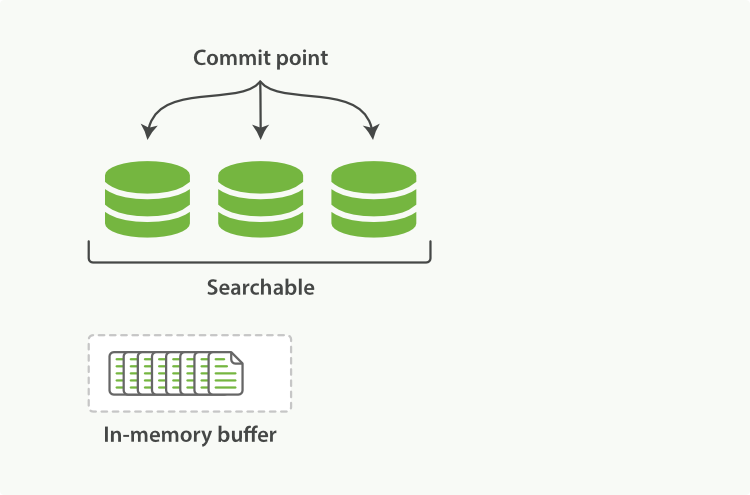
图3:提交后,新的段加到了提交点,缓存被清空
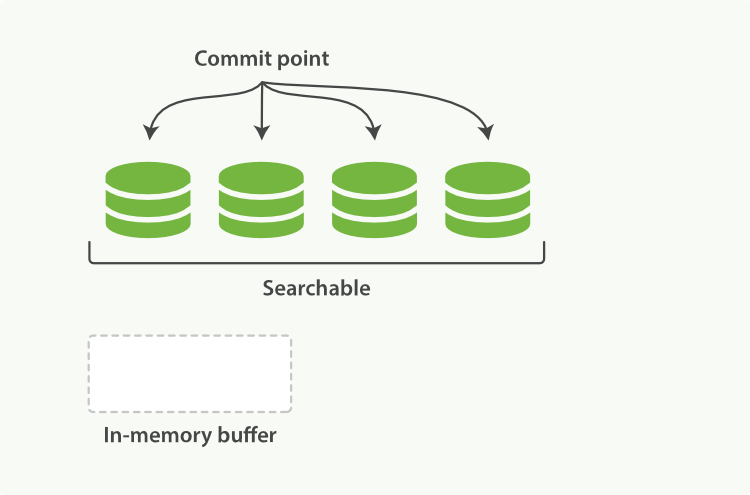
当一个请求被接受,所有段依次查询。所有段上的Term统计信息被聚合,确保每个term和文档的相关性被正确计算。通过这种方式,新的文档以较小的代价加入索引。
删除和更新
段是不可变的,所以文档既不能从旧的段中移除,旧的段也不能更新以反映文档最新的版本。相反,每一个提交点包括一个.del文件,包含了段上已经被删除的文档。 当一个文档被删除,它实际上只是在.del文件中被标记为删除,依然可以匹配查询,但是最终返回之前会被从结果中删除。
4.3 近实时搜索
因为per-segment search机制,索引和搜索一个文档之间是有延迟的。新的文档会在几分钟内可以搜索,但是这依然不够快。
磁盘是瓶颈。提交一个新的段到磁盘需要fsync操作,确保段被物理地写入磁盘,即时电源失效也不会丢失数据。但是fsync是昂贵的,它不能在每个文档被索引的时就触发。
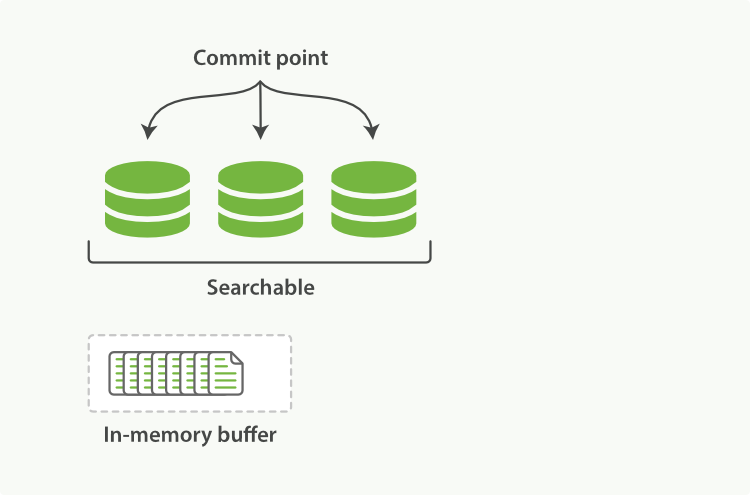
位于Elasticsearch和磁盘间的是文件系统缓存。如前所说,在内存索引缓存中的文档(图1)被写入新的段(图2),但是新的段首先写入文件系统缓存,这代价很低,之后会被同步到磁盘,这个代价很大。但是一旦一个文件被缓存,它也可以被打开和读取,就像其他文件一样。
图1:内存缓存区有新文档的Lucene索引
Lucene允许新段写入打开,好让它们包括的文档可搜索,而不用执行一次全量提交。这是比提交更轻量的过程,可以经常操作,而不会影响性能。
图2:缓存内容已经写到段中,但是还没提交
refeash API
在Elesticsearch中,这种写入打开一个新段的轻量级过程,叫做refresh。默认情况下,每个分片每秒自动刷新一次。这就是为什么说Elasticsearch是近实时的搜索了:文档的改动不会立即被搜索,但是会在一秒内可见。
这会困扰新用户:他们索引了个文档,尝试搜索它,但是搜不到。解决办法就是执行一次手动刷新,通过API:
POST /_refresh <1>
POST /blogs/_refresh <2>
4.4 持久化变更
没用fsync同步文件系统缓存到磁盘,我们不能确保电源失效,甚至正常退出应用后,数据的安全。为了ES的可靠性,需要确保变更持久化到磁盘。
当我们通过每秒的刷新获得近实时的搜索,我们依然需要定时地执行全提交确保能从失败中恢复。但是提交之间的文档怎么办?我们也不想丢失它们
ES增加了事务日志(translog),来记录每次操作。有了事务日志,过程现在如下:
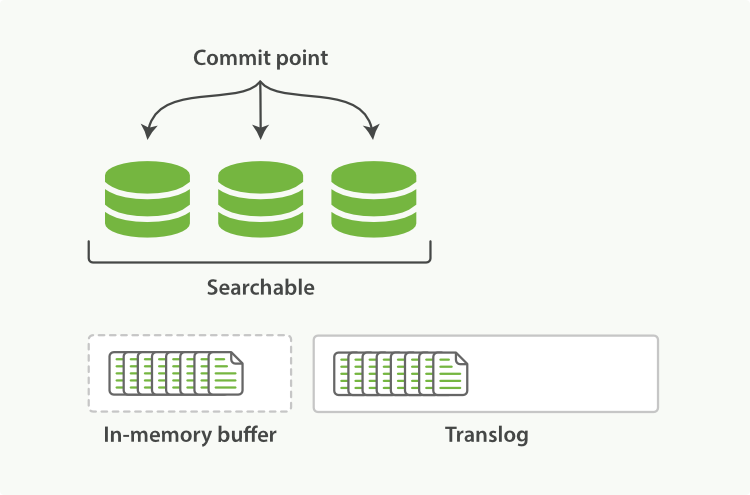
1.当一个文档被索引,它被加入到内存缓存,同时加到事务日志。 图1:新的文档加入到内存缓存,同时写入事务日志
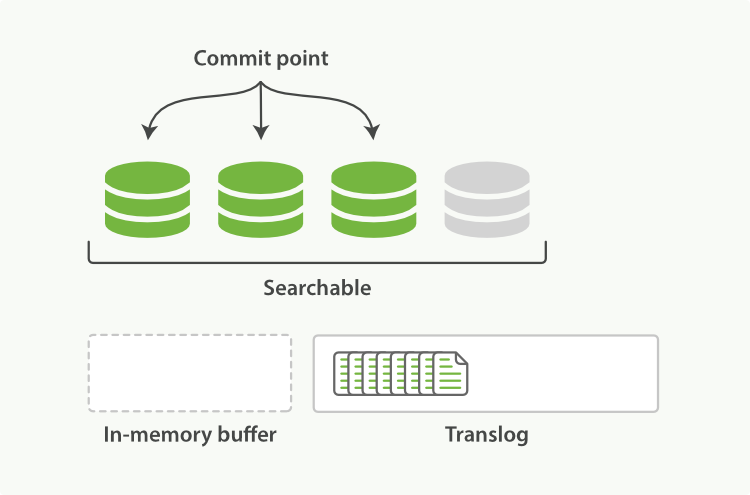
2.refresh使得分片的进入如下图描述的状态。每秒分片都进行refeash:
- 内存缓冲区的文档写入到段中,但没有fsync
- 段被打开,使得新的文档可以被搜索
- 缓存被清除
图2:经过一次refresh,缓存被清除,但事务日志没有
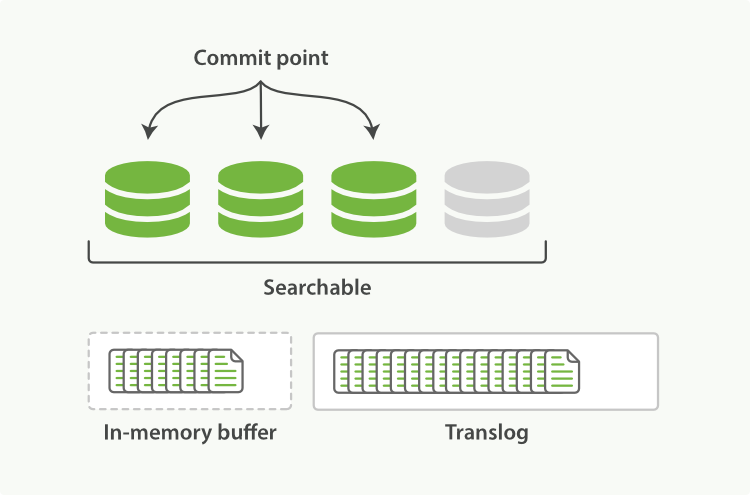
3.随着更多的文档加入到缓存区,写入日志,这个过程会继续 图3:事务日志会记录增长的文档
4.不时地,比如日志很大了,新的日志会创建,会进行一次全提交:
- 内存缓存区的所有文档会写入到新段中。
- 清除缓存
- 一个提交点写入硬盘
- 文件系统缓存通过fsync操作flush到硬盘
- 事务日志被清除 事务日志记录了没有flush到硬盘的所有操作。当故障重启后,ES会用最近一次提交点从硬盘恢复所有已知的段,并且从日志里恢复所有的操作。
事务日志还用来提供实时的CRUD操作。当你尝试用ID进行CRUD时,它在检索相关段内的文档前会首先检查日志最新的改动。这意味着ES可以实时地获取文档的最新版本。
图4:flush过后,段被全提交,事务日志清除
flush API
在ES中,进行一次提交并删除事务日志的操作叫做 flush。分片每30分钟,或事务日志过大会进行一次flush操作。
POST /blogs/_flush <1>
POST /_flush?wait_for_ongoing <2>
4.5 合并段
通过每秒自动刷新创建新的段,用不了多久段的数量就爆炸了。有太多的段是一个问题。每个段消费文件句柄,内存,cpu资源。更重要的是,每次搜索请求都需要依次检查每个段。段越多,查询越慢。
ES通过后台合并段解决这个问题。小段被合并成大段,再合并成更大的段。
这是旧的文档从文件系统删除的时候。旧的段不会再复制到更大的新段中。
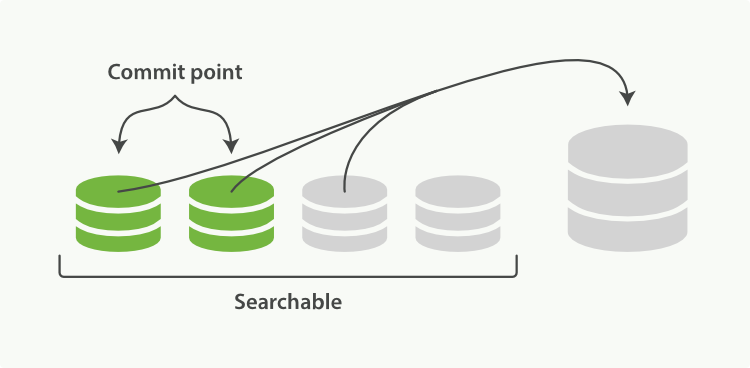
这个过程你不必做什么。当你在索引和搜索时ES会自动处理。这个过程如图:两个提交的段和一个未提交的段合并为了一个更大的段所示:
- 1.索引过程中,refresh会创建新的段,并打开它。
- 2.合并过程会在后台选择一些小的段合并成大的段,这个过程不会中断索引和搜索。
图1:两个提交的段和一个未提交的段合并为了一个更大的段
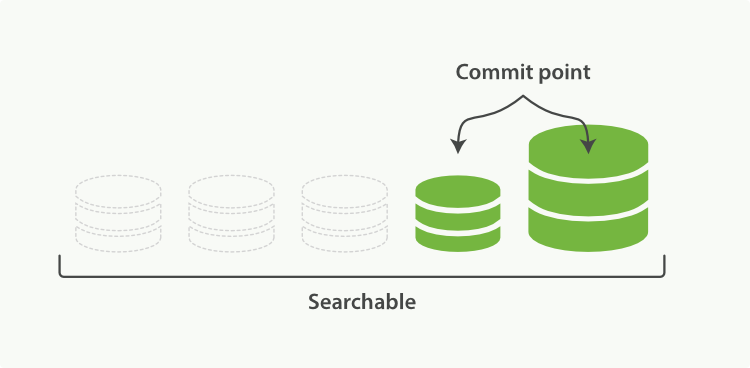
- 3.下图描述了合并后的操作:
- 新的段flush到了硬盘
- 新的提交点写入新的段,排除旧的段
- 新的段打开供搜索
- 旧的段被搜索
图2:段合并完后,旧的段被删除
合并大的段会消耗很多IO和CPU,如果不检查会影响到搜素性能。默认情况下,ES会限制合并过程,这样搜索就可以有足够的资源进行。
optimize API
optimize API最好描述为强制合并段API。它强制分片合并段以达到指定max_num_segments参数。这是为了减少段的数量(通常为1)达到提高搜索性能的目的。