简介 2017-09-10
Hadoop MapReduce作业被分成一系列运行在分布式集群中的map任务和reduce任务。每个任务都工作在被指定的数据子集上,因此负载是遍布集群中各个节点上的。map任务主要负责数据的载入、解析、转换和过滤。每个reduce任务负责处理map任务输出结果的一个子集。然后,reducer任务从mapper任务处复制map任务的中间数据,进行分组和聚合操作。
MapReduce作业的输入是一系列存储在Hadoop分布式文件系统(HDFS)上的文件。在Hadoop中,这些文件通过输入格式被分成了一系列的输入split。输入split可以看着是文件在字节层面的分块表示,每个split由一个map任务负责处理。
Hadoop中的每个map任务可以细分成4个阶段:record reader、mapper、combiner和partitioner。map任务的输出称为中间键和中间值,会被发送到reducer做后续处理。reduce任务可以被分为4个阶段:混排(shuffle)、排序(sort)、reducer和输出格式(output format)。map任务运行的节点会优先选择在数据所在的节点,因此,一般可以通过在本地机器上进行计算来减少数据的网络传输。
reocrd reader
record reader通过输入格式将输出split解析成记录。record reader的目的是将输入数据解析成记录,但不负责解析记录本身。它将数据转换为键/值对的形式,并传递给mapper处理。
mapper
在mapper中,用户定义的map代码通过处理record reader解析的每个键/值对来产生0个或多个新的键/值对结果。键/值的选择对MapReducer作业的完成效率来说非常重要。
combiner
combiner是一个可选的本地reducer,可以在map阶段聚合数据。combiner通过执行用户指定的来自mapper的中间键对map的中间结果做单个map范围内的聚合。
partitioner
partitioner的作用是将mapper输出的键/值对拆分为分片(shard),每个reducer对应一个分片。默认情况下,partitioner先计算目标的散列值。然后通过reducer个数执行取模运算key.hashCode()%(reducer_num)。
混排和排序
reduce任务开始于混排和排序这一步骤。该步骤主要是将所有partitioner写入的输出文件拉取到运行reducer的本地机器上,然后将这些数据按照键排序并写到一个较大的数据列表中。排序的目的是将相同的键记录聚合在一起,这样对其所对应的值就可以很方便地在reduce任务中进行迭代处理。这个过程完全不可定制,而且是由框架自动处理的。开发人员只能通过自定义Comparator对象来确定键如何排序和分组。
reduce
reducer将已经分好组的数据作为输入,并依次为每个键对应分组执行reduce函数。reduce函数的是键以及包含与该键对应的所有值的迭代器。当reduce函数执行完毕后,会将0个或多个键/值对发送到最后的处理步骤——输出格式。reduce函数是业务处理逻辑的核心部分,所以不同作业的reduce函数也不相同。
输出格式
输出格式获取reduce函数输出的最终键/值对,并通过record writer将它写入到输出文件中。每条记录的键和值默认值通过tab分隔,不同记录通过换行符分隔。
Mapper处理流程
在作业提交完成之后,就开始执行Map Task任务了,Mapper的任务就是执行用户的Map()函数将输入键值对(key/value pair)映像到一组中间格式的键值对集合。
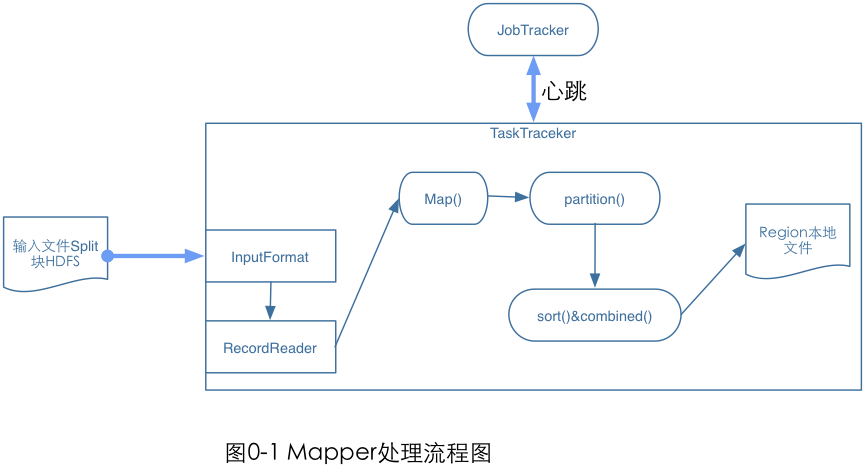 图中是Mapper的处理流程图。Mapper的输入文件在HDFS上;InputFormat接口描述文件的格式信息,通过这个接口可以获得InputSplit的实现,然后对输入的数据进行切分;每一个Split分块对应一个Mapper任务,通过RecorReader对象从输入分块中读取并生成
图中是Mapper的处理流程图。Mapper的输入文件在HDFS上;InputFormat接口描述文件的格式信息,通过这个接口可以获得InputSplit的实现,然后对输入的数据进行切分;每一个Split分块对应一个Mapper任务,通过RecorReader对象从输入分块中读取并生成<k,v>键值对;Map函数接收这些键值对更具用户的map函数进行处理后输出<k1,v1>键值对,Map函数通过context.collect方法将结果写到context对象中;当Mapper的输出键值对被收集后,他们会被partitioner类中的partition()函数以指定的分区写到输出缓冲区,同时调用sort函数对输出进行排序,如何用户为mapper指定了Combiner,则在输出它的键值对<k1,v1>时,不会马上写到缓冲区中,会被收集到list对象上,当写入一定数量的键值对,这部分缓冲会被Combiner中的combine函数合并,然后输出被写入本地文件系统之后会进入Reduce阶段。
Reducer处理流程
Reducer有三个主要阶段:Shuffer、Sort和Reduce,处理流程图为:
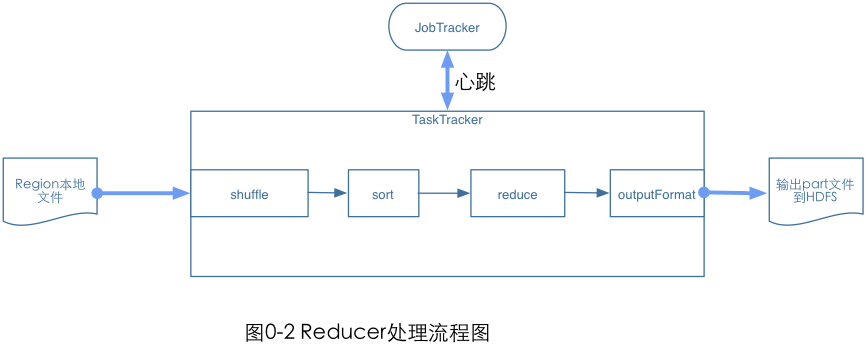 Reducer的整个处理流程为:
Reducer的整个处理流程为:
1、Shuffle阶段,此时Reducer的输入就是Mapper已经排序好的输出。可以理解为混洗阶段,相当于数据复制阶段。
2、Sort阶段,按照key值对Reducer的输入进行分组,Shuffle和Sort是同时进行的。
3、Reduce阶段,通过前两个阶段得到的`<key,(list of values)>`会送到Reducer中的reduce()函数中处理。输出的结果通过OutputFormat输出到DFS中。