分层结构
模式描述
目的:将基于行的数据转化成分层的格式,如Json或XML。
动机
当从RDNMS中奖数据迁移至Hadoop系统时,首先需要考虑的是将数据重新格式化成对计算更为有利的结构。因为Hadoop并不关心数据格式,所以应该充分利用分层数据以避免连接操作。
适用范围
以下场景适合使用该模式:
- 数据源被外键链接;
- 数据是结构化的并且是基于行的。
结构
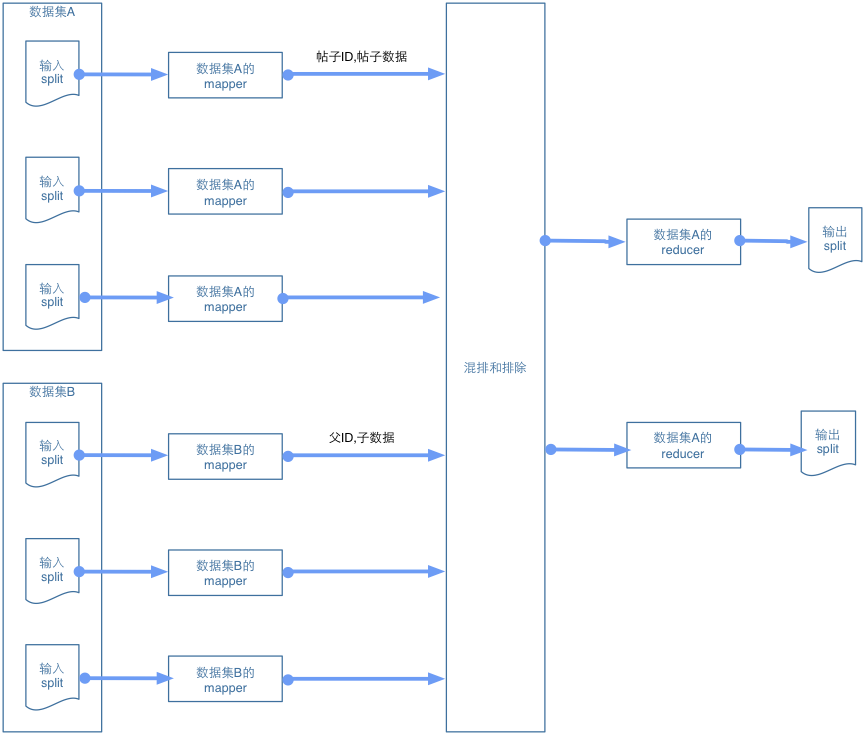
该模式的结构如下图所示,各组件详细描述如下:
- 如果想把多个数据源合并成分层数据结构,Hadoop中的MultipleInputs类将十分有用。MultipleInputs类允许为每一个输入指定不同的路径以及不同的mapper类。相关配置在驱动程序中完成。如果该模式的输入数据源只有一个,则不需要这一步。
- mapper读入数据并将记录解析成更简洁的格式,这样讲更便于reducer处理。输出键代表如何确定分层记录的根。
- 一般来说,combiner在这里没有太大帮助。这里或许可以将具有相同键的项先合并,然后再一起发出去,但此处并不会取得多大的压缩效果,因为要做的就是连接字符串,所以结果字符串的大小与输入的是相同的。
- 不同来源的数据按照键依次发送至reducer。一个特定分组的数据将会保存在一个迭代器中,因此剩下需要做的就是根据数据项列表建立分层数据结构。使用XML或JSON格式,则仅需建立一个对象,然后作为输出写出来即可。
结果
结果将以分层的形式输出,并按照你指定的键分组。
性能分析
使用这个模型时有两个性能指标需要关注:第一,需要知道mapper发送了多少数据给reducer;第二.需要知道reducer构建的对象占用了多少内存。
由于按键分组的记录零散地分布在整个数据集中,因此大量的数据需要通过网络迁移。正是由于这个原因,在使用时需要特别注意:必须有足够数量的reducer。由于所有数据都需要通过网络混排,因此在这里使用策略也可以应用在其他模型中。
另一个重点关注的是数据中存在热点的可能性。热点可能会导致产生非常大的记录。如果你在构建某种对象,所有的评论在输出前的某一刻均存储在内存中,这将可能导致Java虚拟机堆栈溢出,但其实这种情况是可以避免的。
热点带来的另一个问题是数据倾斜,即不同reducer处理的数据量差别很大。该问题在任何MapReducer作业中都有可能发生。在大多数情况下,数据倾斜可以忽略,但是如果数据倾斜真的对应产生影响,那么需要通过自定义partitioner的方式将数据拆分得更为均匀。