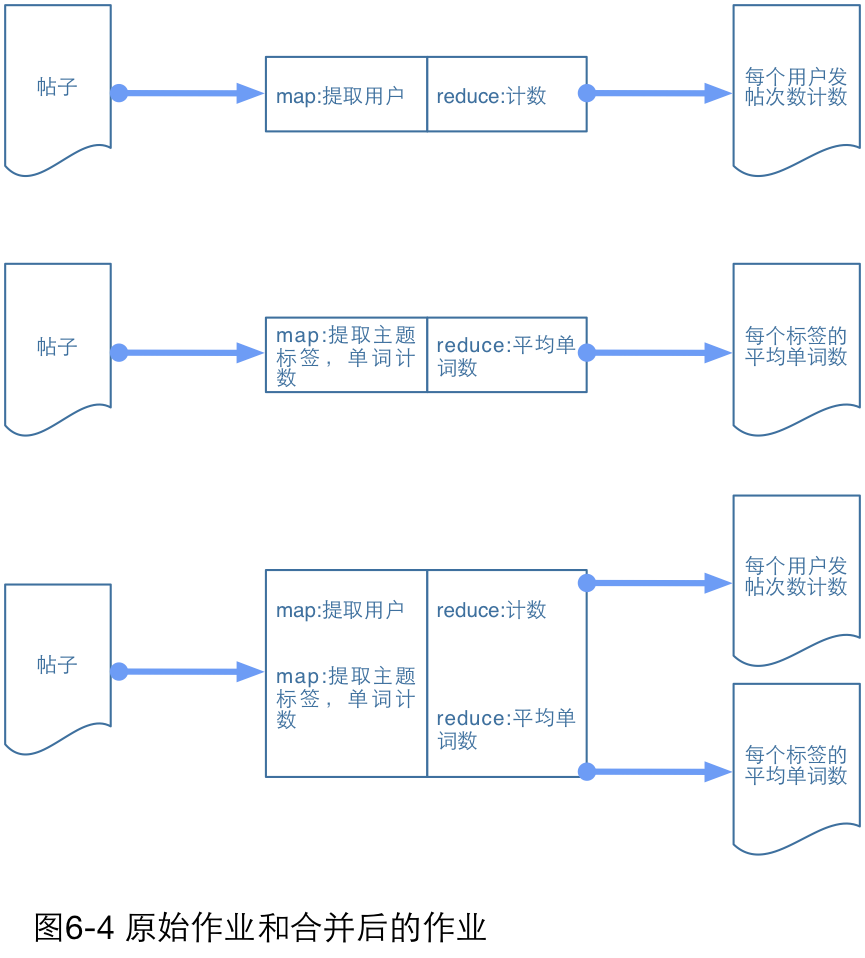
作业归并
作业归并是另一种减少MapReduce管道I/O量的优化方法。通过作业归并可以使得加载同一份数据的两个不相关作业共享MapReduce管道。作业归并最主要的优点是数据和解析一次。对于某些大型的作业来说,这有可能是整个操作中代价最高昂的部分。采用“schema-on-load”模式,并且数据按原始格式存储的一个缺点是使用时必须反复解析数据,如果解析过程比较复杂,这将会影响性能。
假设我们有两个作业需要运行在完全相同的庞大数据量上。这两个作业都需要加载并解析数据,然后执行它们的计算。通过作业归并,我们将使用一个MapReduce作业在逻辑上执行两个作业,并且不需要将两个应用混在一起。原始作业链经过优化后,使得两个mapper运行在同一份数据上,并且两个reduce也运行在同一份数据上。
在应用这个模式之前必须满足一些先决条件。最明显的一个是两个作业必须有相同的中间键及输出格式,因为它们将共享管道,因而需要使用相同的数据类型。
作业归并是一个脏过程。要想让它工作必须得能熟练地修改代码,但是肯定可以在归并的解决方案中增加一些工作,使其变的更整洁。从软件工程的角度来看,这会使得代码组织更加复杂,因为不想关的代码的作业现在需要共享代码。在更高级别来说,相同的map函数将和旧的map函数执行一样的功能,然而reduce函数将基于键中的标签执行一个或另一个动作,键中的标签说明这条记录来自于哪个数据集。将两个作业归并的步骤如下:
1.将两个mapper的代码放在一起。 有两种方法可以做到这一点,一种是代码复制和粘贴,会使得代码结构混乱。另一种方法是将这些代码分成两个辅助map函数,每个辅助函数按照自己的算法处理输入数据。
2.在mapper中,生成键和值时,需要“用标签标记”键以区分map源。
3.在reducer中,在解析出标签后使用if语句切换到相应的reducer代码中取实际执行。
4.使用multipleOutputs将作业的输出分开。 MultipleOutputs是一个特殊的输出格式辅助类。它允许你字啊同一个reducer中奖输出写到不同的文件夹,而不是单一的文件夹中。通过它使得一个reducer的输出路径总是写到MultipleOutputs的一个文件夹中,而其他reducer的输出路径写到另外的文件夹。