分区裁剪
模式描述
分区裁剪模式将通过配置决定框架如何选取输入split以及如何基于文件名过滤加载到MapReduce作业的文件。
目的
如果你有一组按照预先确定的值进行分区的数据,那么通过该模式能够根据应用需求动态地加载数据。
动机
通常来说,加载到MapReduce作业的所有数据都将分配给map任务,map任务则按照并行方式读取。如果根据查询请求要丢弃全部文件,那么加载全部这些文件将浪费大量的处理时间。如果按照一个公用值对数据分区,那么仅在数据可能存在的区域查找,将节省大量的处理时间。
一种良好的是想方式是将数据在文件系统的存储方式剥离出去,单独放到输入格式中。这个输入格斯知道数据在哪里并且如何去获取,同时也允许根据查询请求改变生成的map任务数量。
结构
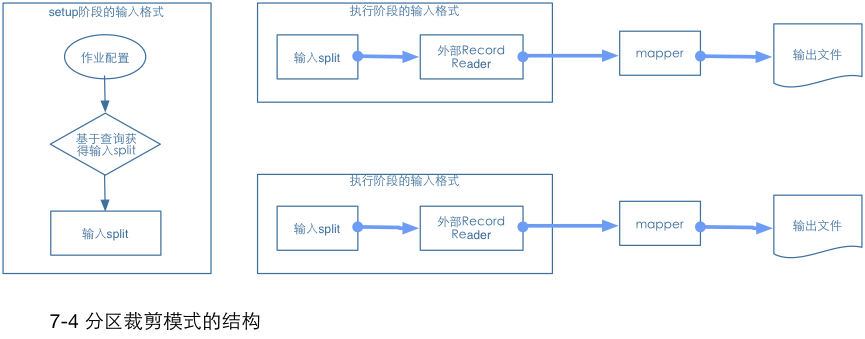
分区裁剪的结构如下:
- 分区裁剪模式是在InputFormat中实现的。其中,getSplits方式是需要我们特别注意的,因为它确定了要创建的输入split,进而确定map任务的个数。虽然作业配置通常是一组文件,但是作业配置更多是转换成一个查询请求而不是一组文件路径。
- RecordReader的实现依赖于数据是如何存储的。如果它是基于文件的输入,那么像LineRecordReader就能用来从文件中读取键/值对。如果它是外部源,那么你将不得不自定义某些东西来满足你的需求。
结果
分区裁剪只改变MapReduce作业读取的数据量,而不会影响分析的最终输出结果。进行分区裁剪的主要原因是减少读取数据的总处理时间。它是通过在map任务执行之前将不会产生任何输出结果的输入过滤掉来实现的。