分区
模式描述
分区模式是将记录进行分类(即分片、分区或分箱),但它并不关心记录的顺序。
目的
该模式的目的是将数据集中相似的记录分成不同的、更小的数据集。
动机
假设想查看一个特定的数据集,其中的数据项通常是分散在整个数据集中。因此,哪怕是查看一个子集,也需要扫描整个数据集的所有数据。分区意味着将一个大的数据集拆分成更小的子集,这样你在分析中就可以通过相关规则选取这些数据集。为了提升性能,你可以运行一个作业对数据集进行分区,并输出到不同的文件中。这样,当需要分析数据中某个特定的子集时,相关作业仅需要查看相应的那部分数据即可。
除了必须构建分区,分区模式没有什么缺点。如果需要,Mapreduce作业仍然可以运行在所有分区上。
使用范围
应用该模式的一个最主要的要求是:必须提前知道有多少个分区。
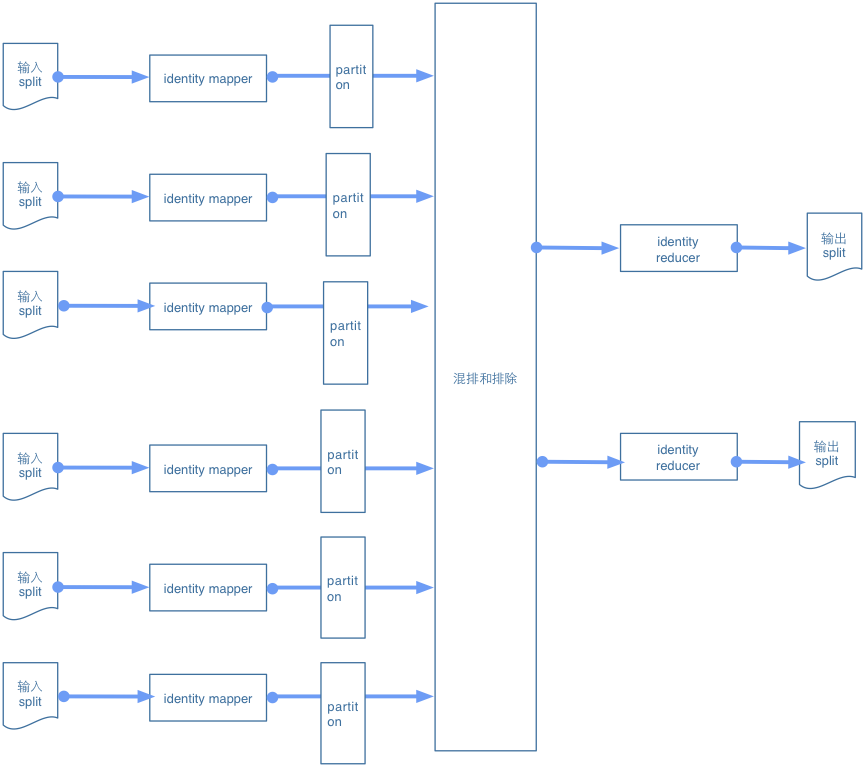
结构
数据是通过分区器进行分区的。这里没有实际的分区逻辑,需要做的是在自定义分区器中自定义函数确定每条记录将分配到哪个分区。结构如下:
- 在大多数情况下,都是使用相同的mapper
- 自定义分区器是这个模式的精华。自定义分区器将决定每条记录发送给哪个reducer,每个reducer对应于哪个特定分区。
- 在大多数情况下,使用identity reducer即可。
结果
在作业的输出文件夹中,每个分区将对应一个输出的part文件。
性能分析
在性能方面该模式的主要关注的是,每个分区的结构数据中是否有相似数据量的记录。有可能一个分区包含整个大数据集中50%的数据。如果不假思索地简单实现该模式,那么所有数据都将发送到一个reducer,此时处理性能将会显著下降。
解决问题很简单。将非常大的分区拆分成几个更小的分区,哪怕是随机拆分也可以。给该分区分配多个reducer,然后随机地将记录分配给每个reducer去展开也会更好。