2.3 计数器计数
模式描述
模式使用MapReduce框架自身的计数器在不产生任何输出的情况下,在map端计算一个全局的计数。
目的
得到大数据集计数概要的一种高效方法
动机
一个计数或者总和可以让你了解到关于数据的某些字段,以至于整个数据集的很多信息。一个reduce可以汇总所有的输入值,并输出这个小时的最终记录计数。虽然这种方式可以解决问题,但使用计数器将更有效率。不需要像MapReduce程序那样输出键/值对,只需要简单地使用框架的计数机制来跟踪输入记录数。整个过程不需要reduce阶段和汇总处理,框架负责监视计数器的名称和其对应的值,对所有任务的结果进行聚合,同时还会记录失败任务的重试计数。
框架中已经内置了一些计数器的支持,例如输入、输出的记录数和字节数。Hadoop支持开发者根据自己的需要创建自定义函数。这个模式阐述的就是如何使用这些自定义计数器来手机和汇总数据集的指标信息。使用计数器的最大好处是整个技术的过程都可以在map阶段完成。
适用场景
适合使用计数器的场景如下:
- 在一个大数据集上收集计数或汇总。
- 需要创建的计数器数目很小——两位数字以内。
结构
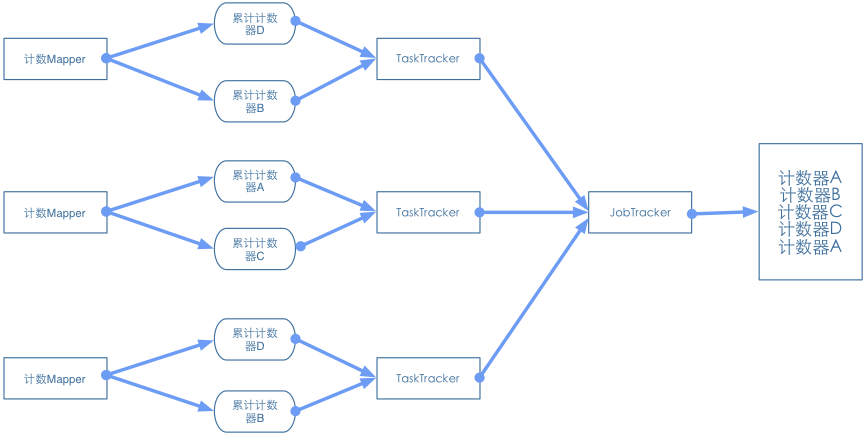
下图显示了在MapReducer框架下这个模式的工作原理:
mapper在每次处理每个输入记录时,按照既定的条件对计数器进行累加。计数器在对单个实例进行计数时会加1,在执行汇总时会增加一个指定的值。这些计数器信息会被负责执行这个任务的TaskTracker聚合并增量汇报给JobTracker,以工作完成的时候做整体聚合。对应的失败任务的计数器,JobTracker会在最终的汇总中将其剔除。
所有的工作只需要在map过程中完成,不需要combiner、Partitioner或reducer过程。
结果
最终的输出是这个任务框架中所得到的所有计数器信息的集合,并不是分析任务的真实输出结果。但是作业的执行总是需要一个输出目录的,这个目录会存在并包含一系列与map任务数目相同的空part文件。
性能分析
使用计数器是非常快速的,因为数据只是在mapper端被读入,并没有任何的输出记录。分析的效率很大程度取决于map任务的数目以及每条记录的处理时间。