链折叠
链折叠是应用于MapReduce作业链的一种优化方法。基本上,它是一个经验法则,即每条记录都可以提交至多个mapper或一个reducer,然后再交给一个mapper。这种合并处理能减少很多读取文件和传输数据的时间。作业的这种结构使得该方法通常都是可行的,因为map的阶段是完全无共享的:由于每条记录都是单独处理,因此map并不关心数据的组织形式或者数据有没有分组。在构建大的MapReduce作业链时,通过将作业链折叠,使得map阶段合并起来将带来十分显著的性能提升。
链折叠的主要优点在于减少在MapReduce管道中移动的数据量,不管是从磁盘中加载和存储数据的I/O,还是通过网络混排的数据。在链接的MapReudce作业中,临时数据存储在HDFS中,因此如果我们能够较少访问磁盘的次数,我们就能减少整个作业链的I/O总量。
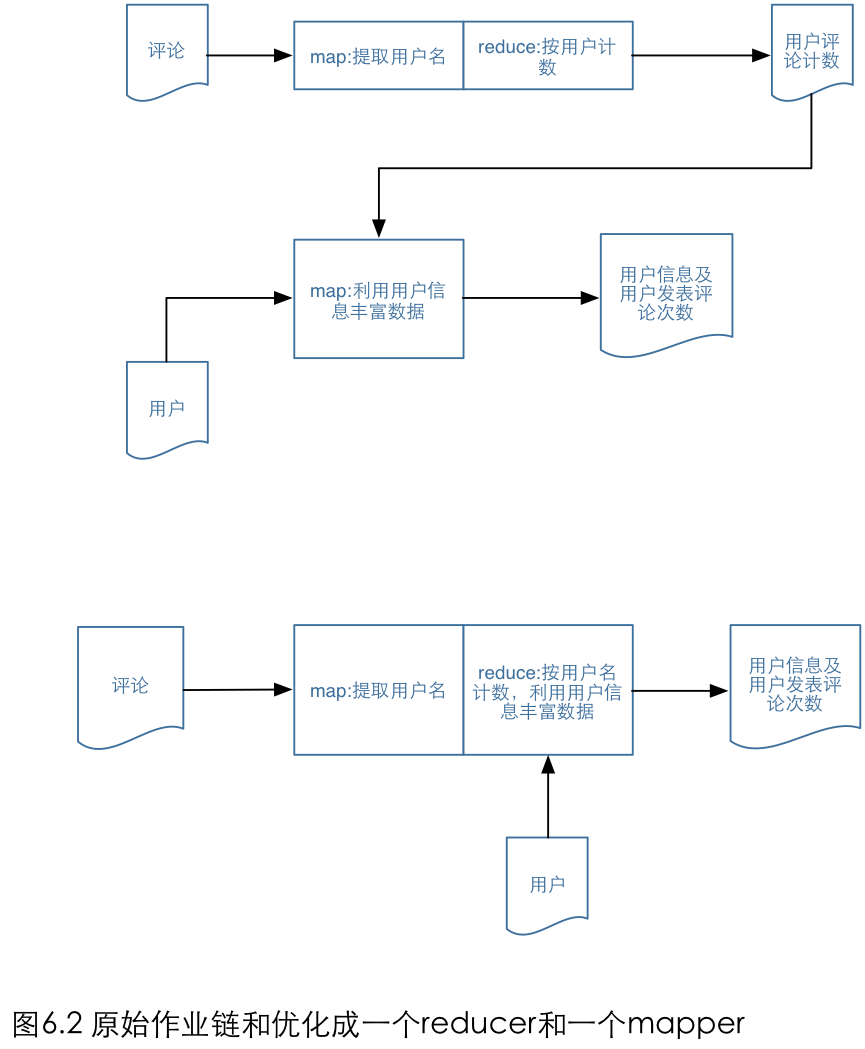
在作业链中有许多模式,可以通过下面介绍的这些方法来查找和确认那些可以折叠: 1.看看作业链的map阶段。如果多个map阶段是相临的,将它们合并到一个阶段。 如果你有一个只有map的作业,并且紧随其后的是数值聚合,那么就符合这种情况。在这一步中,我们需要减少访问磁盘的次数。考虑一个只有两个作业的作业链,且第一个作业只有map,其后是一个传统的MapReduce作业,这个作业有一个map阶段和一个reduce阶段。如果没有这个优化,第一个只有map的作业会将输出写到分布式文件系统中,随后这些数据将被第二个作业加载。 相反,如果我们将只有map的作业和传统作业的map阶段合并,那么就不用写临时数据了,这将显著地减少I/O量。同时,这也会减少启动任务,以及管理任务的开销。把很多map任务链接在一起将是更加惊人的优化。在这中场景中,除了可能需要改变现有代码外,真的没有任何缺点。

2.如果作业以map阶段结束,将这个阶段移到前一个reducer里面。这是一种特殊情况,它的性能优势和前面的步骤一样。它去除了写临时数据的I/O的操作,然后再reduce中执行只有map的作业。这同样也能减少任务启动的开销。
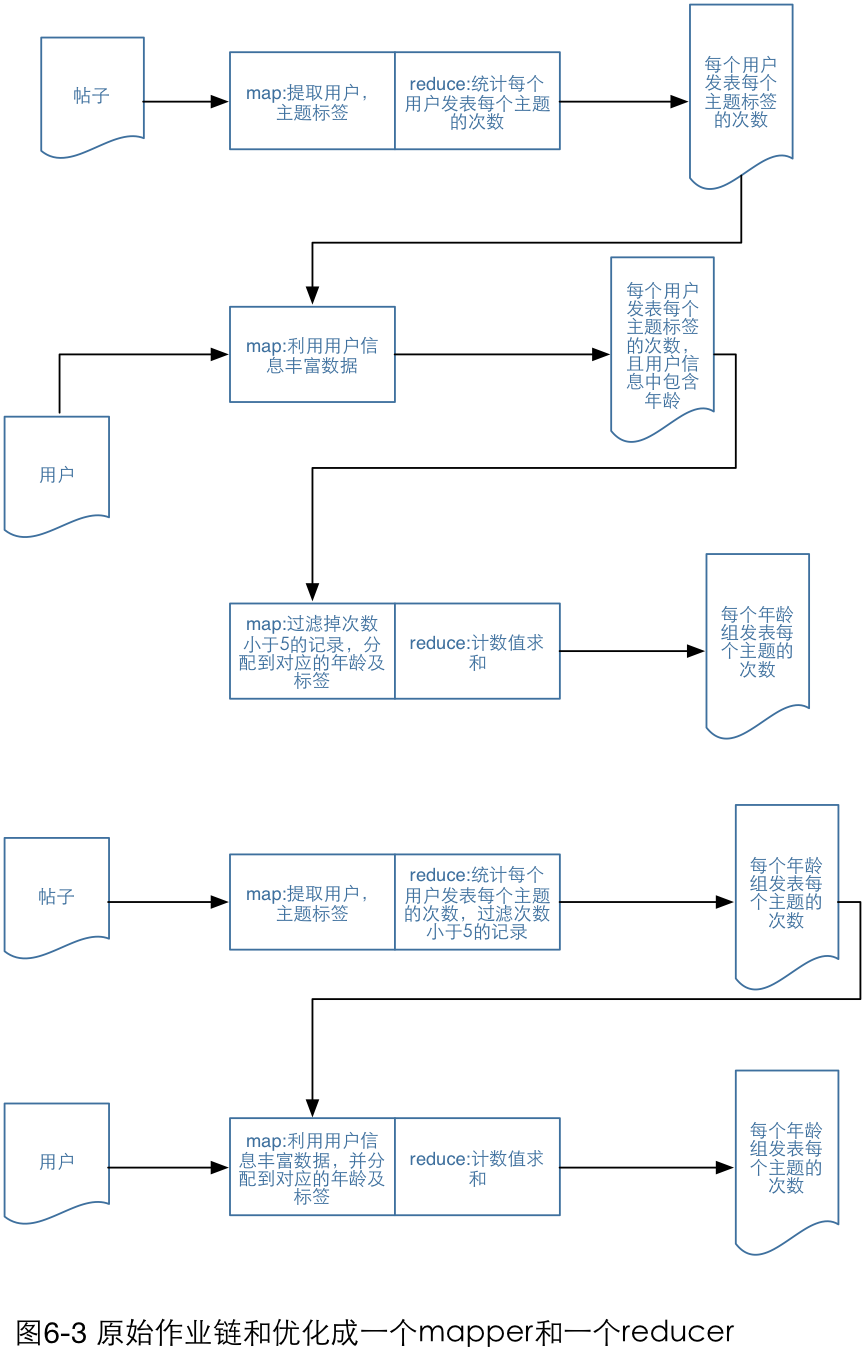
3.注意,作业链的第一个map阶段无法从下一个优化中获益。尽可能地减少数据量的操作和增加数据量的操作之间拆分每个map阶段。在某些情况下,这是不可能的,因为你为了过滤,可能需要更丰富的数据。在某些情况下,这是不可能的,因为你为了过滤,可能需要更丰富的数据。在这些情况下,吧依赖阶段看成一个更大的阶段,这个阶段是慢慢增加或减少数据量。将减少数据量的处理过程放到前一个reducer中,同时将增加数据量的处理过程保持在原来位置。
这个步骤有一些复杂并且有一些细微的不同。这里的收益在于,如果你将最小化的map阶段处理过程并入到前一个reducer,这不但会减少写入临时存储的数据量,而且也会减少从磁盘加载数据到作业链的下一个部分的数据量。如果做出了大量的过滤,那么效果将会更为显著。