Top 10
模式描述
Top 10模式跟前文提到的所有模式的不同是,不管输入数据的大小是多少,你都可以精确地知道输出的结果的记录数。在普通的过滤模式中,输出数据的数量由输入数据决定。
目的
无论数据集的大小如何,根据数据集的排名方案,都能得到一个相对较小的top K记录集合。
动机
找出异类是数据分析中的一个重要部分,因为这些记录通常是数据集中最为有趣和独特的部分。这个模式的重点是找出某一特定标准下的最好记录集,由此可以进一步分析这些数据并可能找出是什么导致这部分数据如此独特的原因。如果你可以定义一个排名函数或者比较函数,用于确定两条记录之间那一条比另一条更高,那么你可以应用这个模式来通过MapReduce找出整个数据集中最有价值的记录。
适用场景
- 这个模式需要一个比较两条记录的比较函数。也就是说,我们必须得通过比较确认两条记录中哪一个更大一些。
- 输出记录数相对于输入记录数将会是异常的小,否则获得整个数据集的全排序将会更有意义。
结构
这个模式同时使用了mapper和reducer。mapper任务找出其本地的topK,然后所有独立的top K集合在reducer中做最后的top K运算。因为在mapper中输出的数据记录最多事K条,而K通常相对较小,所以我们只需要一个reducer来处理最后的运算。
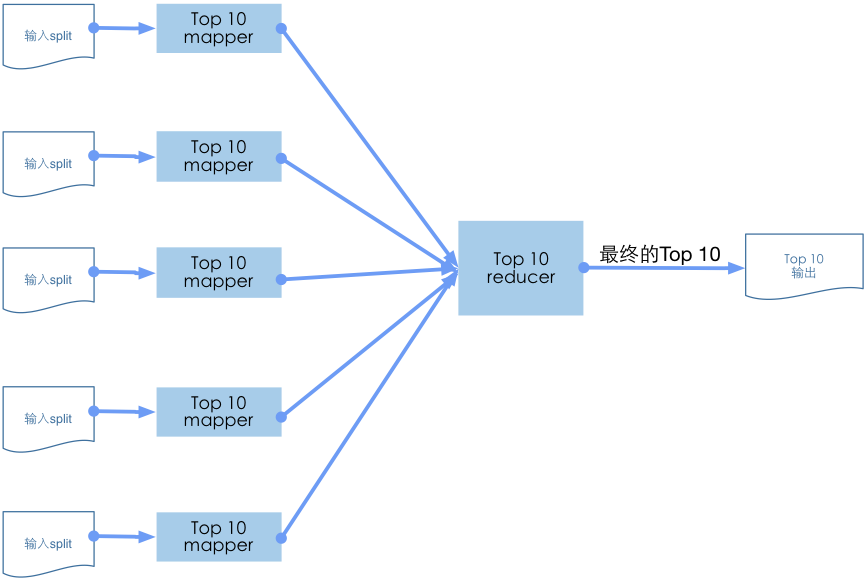
mapper读取每一条记录并收集最大的K条记录保留在一个大小为K的数组对象中。在mapper的cleanup阶段,我们奖存储在队列中的K条记录作为值,并将键置为null,将记录发出,这将对应这个map任务中最大的K值。
对同一个键null,我们将期望得到K*M个记录来到reducer阶段,其中M是总的map任务数。在reduce函数只能怪,我们将与mapper函数的处理一致:保留一个K个值的数组,对应键为null,找出top K个值。
从每一个mapper中找出其top K的原因是:有可能全局的Top记录都来自于同一个文件的split,因此要考虑这种极端的情况。
结果
返回top k条记录。
性能分析
Top 10模式的性能通常都是很好的,但是有一些重要的局限性需要考虑。大多数局限性都来源于,不管这个模式需要处理的记录数有多少,它都只能使用一个reducer。
使用这个模式我们需要特别注意的一点是,单一reducer需要处理的记录数目。每一个map任务会输出K条记录,当这个作业由M个map任务组成时,这个reducer需要处理K*M条记录。这个值可能会很大。
让单一reducer处理大量数据很不好,原因有以下几个:
- 需要处理的记录太多会导致不能全部在内存中完成,而必须使用本地磁盘进行大部分的排序操作,此时的操作成本会很高。
- 运行这个reducer的主机需要通过网络获取大量的数据,这将会对单一主机节点产生一个网络资源的热点。
- 自然,如果有太多的记录需要处理,那么全量扫描这个reduce需要处理的全部数据将会花费相当长的时间。
- reducer中的任何内存增长都有可能使得Java虚拟机的内存出现不足。
- 将结果写到输出文件的操作不是并行的。当处理大规模数据的时候,写数据到本地磁盘通常是reduce阶段成本较高的操作。因为只有一个reducer,我们不能得到多个reducer可以在多台主机并行写数据的好处。
当K变大是,这个模式将会变得更低效。当K是一个很大的值,并且输入split的规模也很大的情况下,可以选择的优化方案是预先过滤一些数据,因为你知道上次top 10结果也不能改变多少。